
Redis详解
一、概述
1.1 互联网架构的演变历程
第1阶段
数据访问量不大,简单的架构即可搞定!

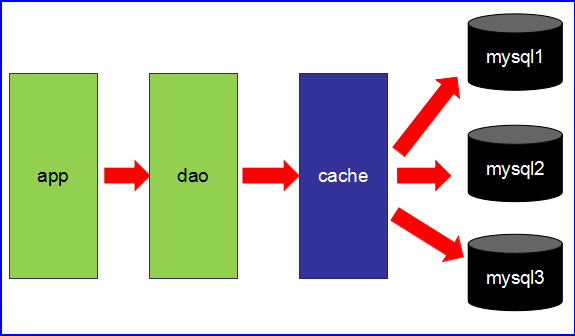
第2阶段
- 数据访问量大,使用缓存技术来缓解数据库的压力。
- 不同的业务访问不同的数据库
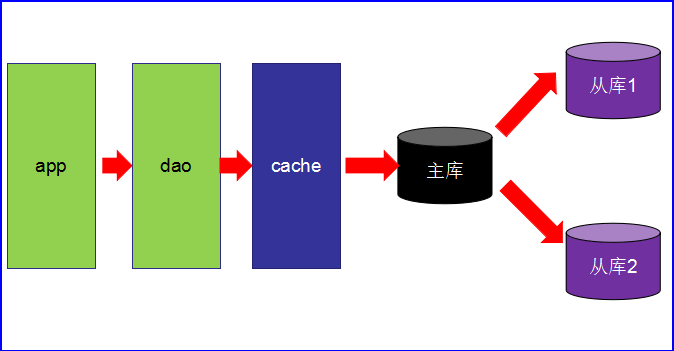
第3阶段
- 主从读写分离。
- 之前的缓存确实能够缓解数据库的压力,但是写和读都集中在一个数据库上,压力又来了。
- 一个数据库负责写,一个数据库负责读。分工合作。愉快!
- 让master(主数据库)来响应事务性**(增删改)操作,让slave(从数据库)来响应非事务性(查询)**操作,然后再采用主从复制来把master上的事务性操作同步到slave数据库中
- mysql的master/slave就是网站的标配!
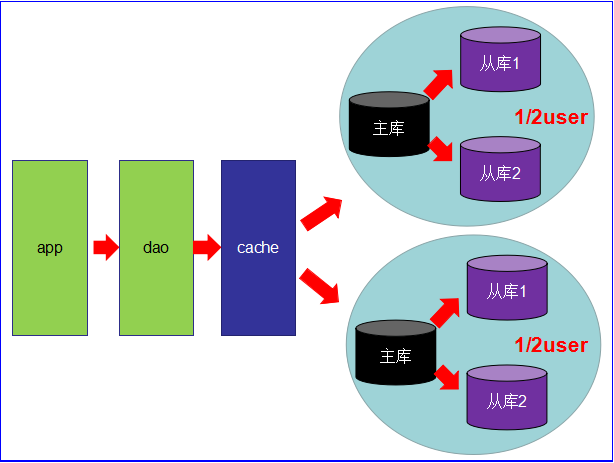
第4阶段
- mysql的主从复制,读写分离的基础上,mysql的主库开始出现瓶颈
- 由于MyISAM使用表锁,所以并发性能特别差
- 分库分表开始流行,mysql也提出了表分区,虽然不稳定,但我们看到了希望
- 开始吧,mysql集群
1.2 Redis入门介绍
- 互联网需求的3高
- 高并发,高可扩,高性能
- Redis 是一种运行速度很快,并发性能很强,并且运行在内存上的NoSql(not only sql)数据库
- NoSQL数据库 和 传统数据库 相比的优势
- NoSQL数据库无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。
- 而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦
- Redis的常用使用场景
- 缓存,毫无疑问这是Redis当今最为人熟知的使用场景。在提升服务器性能方面非常有效;一些频繁被访问的数据,经常被访问的数据如果放在关系型数据库,每次查询的开销都会很大,而放在redis中,因为redis 是放在内存中的可以很高效的访问
- 排行榜,在使用传统的关系型数据库(mysql oracle 等)来做这个事儿,非常的麻烦,而利用Redis的SortSet(有序集合)数据结构能够简单的搞定;
- 计算器/限速器,利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力;限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力;
- 好友关系,利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好友、共同爱好之类的功能;
- 简单消息队列,除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦;
- Session****共享,以jsp为例,默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息。
1.3 Redis/Memcache/MongoDB对比
都是nosql数据库的著名代表
1.3.1 Redis和Memcache
- Redis和Memcache都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等。
- memcache 数据结构单一kv,redis 更丰富一些,还提供 list,set, hash 等数据结构的存储,有效的减少网络 IO 的次数
- 虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value交换到磁盘
- 存储数据安全–memcache挂掉后,数据没了(没有持久化机制);redis可以定期保存到磁盘(持久化)
- 灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过RBD或AOF恢复
1.3.2 Redis和MongoDB
- redis和mongodb并不是竞争关系,更多的是一种协作共存的关系。
- mongodb本质上还是硬盘数据库,在复杂查询时仍然会有大量的资源消耗,而且在处理复杂逻辑时仍然要不可避免地进行多次查询。
- 这时就需要redis或Memcache这样的内存数据库来作为中间层进行缓存和加速。
- 比如在某些复杂页面的场景中,整个页面的内容如果都从mongodb中查询,可能要几十个查询语句,耗时很长。如果需求允许,则可以把整个页面的对象缓存至redis中,定期更新。这样mongodb和redis就能很好地协作起来
1.4 分布式数据库CAP原理
1.4.1 CAP简介
- 传统的关系型数据库事务具备ACID:
- A:原子性
- C:一致性
- I:独立性
- D:持久性
- 分布式数据库的CAP:
C(Consistency):强一致性
- “all nodes see the same data at the same time”,即更新操作成功并返回客户端后,所有节点在同一时间的数据完全一致,这就是分布式的一致性。一致性的问题在并发系统中不可避免,对于客户端来说,一致性指的是并发访问时更新过的数据如何获取的问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
A(Availability):高可用性
- 可用性指“Reads and writes always succeed”,即服务一直可用,而且要是正常的响应时间。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。
P(Partition tolerance):分区容错性
- 即分布式系统在遇到某节点或网络分区故障时,仍然能够对外提供满足一致性或可用性的服务。
- 分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,对于用户而言并没有什么体验上的影响。
1.4.2 CAP理论
- CAP理论提出就是针对分布式数据库环境的,所以,P这个属性必须容忍它的存在,而且是必须具备的。
- 因为P是必须的,那么我们需要选择的就是A和C。
- 大家知道,在分布式环境下,为了保证系统可用性,通常都采取了复制的方式,避免一个节点损坏,导致系统不可用。那么就出现了每个节点上的数据出现了很多个副本的情况,而数据从一个节点复制到另外的节点时需要时间和要求网络畅通的,所以,当P发生时,也就是无法向某个节点复制数据时,这时候你有两个选择:
- 选择可用性 A,此时,那个失去联系的节点依然可以向系统提供服务,不过它的数据就不能保证是同步的了(失去了C属性)。
- 选择一致性C,为了保证数据库的一致性,我们必须等待失去联系的节点恢复过来,在这个过程中,那个节点是不允许对外提供服务的,这时候系统处于不可用状态(失去了A属性)。
- 最常见的例子是读写分离,某个节点负责写入数据,然后将数据同步到其它节点,其它节点提供读取的服务,当两个节点出现通信问题时,你就面临着选择A(继续提供服务,但是数据不保证准确),C(用户处于等待状态,一直等到数据同步完成)。
1.4.3 CAP总结
- 分区是常态,不可避免,三者不可共存
- 可用性和一致性是一对冤家
- 一致性高,可用性低
- 一致性低,可用性高
- 因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
二、下载与安装
2.1 下载
redis:http://www.redis.net.cn/
图形工具:https://redisdesktop.com/download
2.2 安装
虽然可以在安装在windows操作系统,但是官方不推荐,一如既往的安装在linux上环境是虚拟机
上传tar.gz包,并解压
1
tar -zxvf redis-5.0.4.tar.gz
安装gcc(必须有网络)
1
yum -y install gcc
进入redis目录,进行编译
1
make
编译之后,开始安装
1 | make install |
2.3 安装后的操作
2.3.1 后台运行方式
- redis默认不会使用后台运行,如果你需要,修改配置文件daemonize=yes,当你后台服务启动的时候,会写成一个进程文件运行。
1 | vim /opt/redis-5.0.4/redis.conf |
1 | daemonize yes |
- 以配置文件的方式启动
1 | cd /usr/local/bin redis-server /opt/redis-5.0.4/redis.conf |
2.3.2 关闭数据库
- 单实例关闭
1 | redis-cli shutdown |
- 多实例关闭
1 | redis-cli -p 6379 shutdown |
2.3.3 常用操作
- 检测6379端口是否在监听
1 | netstat -lntp | grep 6379 |
端口为什么是6379?
6379在是手机按键上MERZ对应的号码,
而MERZ取自意大利歌女Alessia Merz的名字。
MERZ长期以来被antirez(redis作者)及其朋友当作愚蠢的代名词。
- 检测后台进程是否存在
1 | ps -ef|grep redis |
2.3.4 连接redis并测试
1 | redis-cli |
2.3.5 HelloWorld
1 | # 保存数据 |
2.3.6 测试性能
- 先 ctrl+c,退出redis客户端
1 | redis-benchmark |
- 执行命令后,命令不会自动停止,需要我们手动ctrl+c停止测试\
1 | [root@localhost bin]# redis-benchmark |
2.3.7 默认16个数据库
1 | vim /opt/redis-5.0.4/redis.conf |
1 | 127.0.0.1:6379> get k1 # 查询k1 |
2.3.8 数据库键的数量
1 | dbsize |
redis在linux支持命令补全(tab)
2.3.9 清空数据库
- 清空当前库
1 | flushdb |
- 清空所有(16个)库,慎用!!
1 | flushall |
2.3.10 模糊查询(key)
模糊查询keys命令,有三个通配符:
通配任意多个字符
查询所有的键
1
keys *
模糊查询k开头,后面随便多少个字符
1
keys k*
模糊查询e为最后一位,前面随便多少个字符
1
keys *e
双 * 模式,匹配任意多个字符:查询包含k的键
1
keys *k*
?:通配单个字符
模糊查询k字头,并且匹配一个字符
1
keys k?
你只记得第一个字母是k,他的长度是3
1
keys k??
[]:通配括号内的某一个字符
记得其他字母,就第二个字母可能是a或e
1
keys r[ae]dis
2.3.11 键(key)
exists key:判断某个key是否存在
1
2
3
4127.0.0.1:6379> exists k1
(integer) 1 # 存在
127.0.0.1:6379> exists y1
(integer) 0 # 不存在move key db:移动(剪切,粘贴)键到几号库
1
2
3
4
5
6
7
8127.0.0.1:6379> move x1 8 # 将x1移动到8号库
(integer) 1 # 移动成功
127.0.0.1:6379> exists x1 # 查看当前库中是否存在x1
(integer) 0 # 不存在(因为已经移走了)
127.0.0.1:6379> select 8 # 切换8号库
OK
127.0.0.1:6379[8]> keys * # 查看当前库中的所有键
1) "x1"ttl key:查看键还有多久过期(-1永不过期,-2已过期)
1
2127.0.0.1:6379[8]> ttl x1
(integer) -1 # 永不过期time to live 还能活多久
expire key 秒:为键设置过期时间(生命倒计时)
1
2
3
4
5
6
7
8
9
10
11
12
13
14127.0.0.1:6379[8]> set k1 v1 # 保存k1
OK
127.0.0.1:6379[8]> ttl k1 # 查看k1的过期时间
(integer) -1 # 永不过期
127.0.0.1:6379[8]> expire k1 10 # 设置k1的过期时间为10秒(10秒后自动销毁)
(integer) 1 # 设置成功
127.0.0.1:6379[8]> get k1 # 获取k1
"v1"
127.0.0.1:6379[8]> ttl k1 # 查看k1的过期时间'
(integer) 2 # 还有2秒过期
127.0.0.1:6379[8]> get k1
(nil)
127.0.0.1:6379[8]> keys * # 从内存中销毁了
(empty list or set)type key:查看键的数据类型
1
2127.0.0.1:6379[8]> type k1
string # k1的数据类型是会string字符串
三、使用Redis
3.1 五大数据类型
- 操作文档:http://redisdoc.com/
3.1.1 字符串String
set/get/del/append/strlen
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19127.0.0.1:6379> set k1 v1 # 保存数据
OK
127.0.0.1:6379> set k2 v2 # 保存数据
OK
127.0.0.1:6379> keys *
1) "k2"
2) "k1"
127.0.0.1:6379> del k2 # 删除数据k2
(integer) 1
127.0.0.1:6379> keys *
1) "k1"
127.0.0.1:6379> get k1 # 获取数据k1
"v1"
127.0.0.1:6379> append k1 adc # 往k1的值追加数据abc
(integer) 5
127.0.0.1:6379> get k1
"v1adc"
127.0.0.1:6379> strlen k1 # 返回k1值的长度(字符数量)
(integer) 5incr/decr/incrby/decrby:加减操作,操作的必须是数字类型
- incr:意思是increment,增加
- decr:意思是decrement,减少
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22127.0.0.1:6379> set k1 1 # 初始化k1的值为1
OK
127.0.0.1:6379> incr k1 # k1自增1(相当于++)
(integer) 2
127.0.0.1:6379> incr k1
(integer) 3
127.0.0.1:6379> get k1
"3"
127.0.0.1:6379> decr k1 # k1自减1(相当于--)
(integer) 2
127.0.0.1:6379> decr k1
(integer) 1
127.0.0.1:6379> get k1
"1"
127.0.0.1:6379> incrby k1 3 # k1自增3(相当于+=3)
(integer) 4
127.0.0.1:6379> get k1
"4"
127.0.0.1:6379> decrby k1 2 # k1自减2(相当于-=2)
(integer) 2
127.0.0.1:6379> get k1
"2"getrange/setrange:类似between…and…
- range:范围
1
2
3
4
5
6
7
8
9
10
11
12127.0.0.1:6379> set k1 abcdef # 初始化k1的值为abcdef
OK
127.0.0.1:6379> get k1
"abcdef"
127.0.0.1:6379> getrange k1 0 -1 # 查询k1全部的值
"abcdef"
127.0.0.1:6379> getrange k1 0 3 # 查询k1的值,范围是下标0~下标3(包含0和3,共 返回4个字符)
"abcd"
127.0.0.1:6379> setrange k1 1 xxx # 替换k1的值,从下标1开始提供为xxx
(integer) 6
127.0.0.1:6379> get k1
"axxxef"setex/setnx
- set with expir:添加数据的同时设置生命周期
1
2
3
4
5
6127.0.0.1:6379> setex k1 5 v1 # 添加k1 v1数据的同时,设置5秒的声明周期
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> get k1 # 已过期,k1的值v1自动销毁
(nil)- set if not exist:添加数据的时候判断是否已经存在,防止已存在的数据被覆盖掉
1
2
3
4
5
6127.0.0.1:6379> setnx k1 xu
(integer) 0 # 添加失败,因为k1已经存在
127.0.0.1:6379> get k1
"sun"
127.0.0.1:6379> setnx k2 xu
(integer) 1 # k2不存在,所以添加成功mset/mget/msetnx
- m:more更多
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15127.0.0.1:6379> set k1 v1 k2 v2 # set不支持一次添加多条数据
(error) ERR syntax error
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 # mset可以一次添加多条数据
OK
127.0.0.1:6379> keys *
1) "k3"
2) "k2"
3) "k1"
127.0.0.1:6379> mget k2 k3 # 一次获取多条数据
1) "v2"
2) "v3"
127.0.0.1:6379> msetnx k3 v3 k4 v4 # 一次添加多条数据时,如果添加的数据中有已经存在的,则失败
(integer) 0
127.0.0.1:6379> msetnx k4 v4 k5 v5 # 一次添加多条数据时,如果添加的数据 中都不存在的,则成功
(integer) 1getset:先get后set
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15127.0.0.1:6379> getset k6 v6
(nil) # 因为没有k6,所以get为null,然后将k6v6的值添加到数据库
127.0.0.1:6379> keys *
1) "k2"
2) "k5"
3) "k4"
4) "k6"
5) "k3"
6) "k1"
127.0.0.1:6379> get k6
"v6"
127.0.0.1:6379> getset k6 vv6 # 先获取k6的值,然后修改k6的值为vv6
"v6"
127.0.0.1:6379> get k6
"vv6"
3.1.2 列表List
push和pop,类似机枪AK47:push,压子弹,pop,射击出子弹
lpush/rpush/lrange
- l:left 自左向右→添加 (从上往下添加)
- r:right 自右向左←添加(从下往上添加)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18127.0.0.1:6379> lpush list01 1 2 3 4 5 # 从上往下添加
(integer) 5
127.0.0.1:6379> keys *
1) "list01"
127.0.0.1:6379> lrange list01 0 -1 # 查询list01中的全部数据0表示开 始,-1表示结尾
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
127.0.0.1:6379> rpush list02 1 2 3 4 5 # 从下往上添加
(integer) 5
127.0.0.1:6379> lrange list02 0 -1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"lpop/rpop:移除第一个元素(上左下右)
1
2
3
4127.0.0.1:6379> lpop list02 # 从左(上)边移除第一个元素
"1"
127.0.0.1:6379> rpop list02 # 从右(下)边移除第一个元素
"5"lindex:根据下标查询元素(从左向右,自上而下)
1
2
3
4
5
6
7
8
9
10127.0.0.1:6379> lrange list01 0 -1
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
127.0.0.1:6379> lindex list01 2 # 从上到下数,下标为2的值
"3"
127.0.0.1:6379> lindex list01 1 # 从上到下数,下标为1的值
"4"llen:返回集合长度
1
2127.0.0.1:6379> llen list01
(integer) 5lrem:删除n个value
1
2
3
4
5
6
7
8
9
10
11
12
13127.0.0.1:6379> lpush list01 1 2 2 3 3 3 4 4 4 4
(integer) 10
127.0.0.1:6379> lrem list01 2 3 # 从list01中移除2个3
(integer) 2
127.0.0.1:6379> lrange list01 0 -1
1) "4"
2) "4"
3) "4"
4) "4"
5) "3"
6) "2"
7) "2"
8) "1"ltrim:截取指定范围的值,别的全扔掉
- ltrim key begindex endindex
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19127.0.0.1:6379> lpush list01 1 2 3 4 5 6 7 8 9
(integer) 9
127.0.0.1:6379> lrange list01 0 -1
1) "9" # 下标0
2) "8" # 下标1
3) "7" # 下标2
4) "6" # 下标3
5) "5" # 下标4
6) "4" # 下标5
7) "3" # 下标6
8) "2" # 下标7
9) "1" # 下标8
127.0.0.1:6379> ltrim list01 3 6 # 截取下标3~6的值,别的全扔掉
OK
127.0.0.1:6379> lrange list01 0 -1
1) "6"
2) "5"
3) "4"
4) "3"rpoplpush:从一个集合搞一个元素到另一个集合中(右出一个,左进一个)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30127.0.0.1:6379> rpush list01 1 2 3 4 5
(integer) 5
127.0.0.1:6379> lrange list01 0 -1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
127.0.0.1:6379> rpush list02 1 2 3 4 5
(integer) 5
127.0.0.1:6379> lrange list02 0 -1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
127.0.0.1:6379> rpoplpush list01 list02 # list01右边出一个,从左进入到list02的第一个位置
"5"
127.0.0.1:6379> lrange list01 0 -1
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> lrange list02 0 -1
1) "5"
2) "1"
3) "2"
4) "3"
5) "4"
6) "5"lset:改变某个下标的某个值
- lset key index value
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16127.0.0.1:6379> lrange list02 0 -1
1) "5"
2) "1"
3) "2"
4) "3"
5) "4"
6) "5"
127.0.0.1:6379> lset list02 0 x # 将list02中下标为0的元素修改成x
OK
127.0.0.1:6379> lrange list02 0 -1
1) "x"
2) "1"
3) "2"
4) "3"
5) "4"
6) "5"linsert:插入元素(指定某个元素之前/之后)
linsert key before/after oldvalue new value
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28127.0.0.1:6379> lrange list02 0 -1
1) "x"
2) "1"
3) "2"
4) "3"
5) "4"
6) "5"
127.0.0.1:6379> linsert list02 before 2 java # 从左边进入,在list02中的2素之前插入java
(integer) 7
127.0.0.1:6379> lrange list02 0 -1
1) "x"
2) "1"
3) "java"
4) "2"
5) "3"
6) "4"
7) "5"
127.0.0.1:6379> linsert list02 after 2 redis # 从左边进入,在list02中的元素之后插入redis
(integer) 8
127.0.0.1:6379> lrange list02 0 -1
1) "x"
2) "1"
3) "java"
4) "2"
5) "redis"
6) "3"
7) "4"
8) "5"性能总结:类似添加火车皮一样,头尾操作效率高,中间操作效率惨;
3.1.3 集合Set
和java中的set特点类似,不允许重复
sadd/smembers/sismember:添加/查看/判断是否存在
1
2
3
4
5
6
7
8
9
10127.0.0.1:6379> sadd set01 1 2 2 3 3 3 # 添加元素(自动排除重复元素)
(integer) 3
127.0.0.1:6379> smembers set01 # 查询set01集合
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> sismember set01 2
(integer) 1 # 存在
127.0.0.1:6379> sismember set01 5
(integer) 0 # 不存在- 注意:1和0可不是下标,而是布尔。1:true存在,2:false不存在
scard:获得集合中的元素个数
1
2127.0.0.1:6379> scard set01
(integer) 3 # 集合中有3个元素srem:删除集合中的元素
- srem key value
1
2127.0.0.1:6379> srem set01 2 # 移除set01中的元素2
(integer) 1 # 1表示移除成功srandmember:从集合中随机获取几个元素’
- srandmember 整数(个数)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22sadd set01 1 2 3 4 5 6 7 8 9
(integer) 9
smembers set01
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
9) "9"
srandmember set01 3 # 从set01中随机获取3个元素
1) "8"
2) "2"
3) "3"
srandmember set01 5 # 从set01中随机获取5个元素
1) "5"
2) "8"
3) "7"
4) "4"
5) "6"spop:随机出栈(移除)
1
2
3
4
5
6
7
8
9
10
11
12
13
14smembers set01
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
9) "9"
spop set01 # 随机移除一个元素
"8"
spop set01 # 随机移除一个元素
"7"smove:移动元素:将key1某个值赋值给key2
1
2
3
4
5
6127.0.0.1:6379> sadd set01 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd set02 x y z
(integer) 3
127.0.0.1:6379> smove set01 set02 3 # 将set01中的元素3移动到set02中
(integer) 1 # 移动成功数学集合类
- 交集:sinter
- 并集:sunion
- 差集:sdiff
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24127.0.0.1:6379> sadd set01 1 2 3 4 5
(integer) 5
127.0.0.1:6379> sadd set02 2 a 1 b 3
(integer) 5
127.0.0.1:6379> sinter set01 set02 # set01和set02共同存在的元素
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> sunion set01 set02 # 将set01和set02中所有元素合并起来(排除重复的)
1) "5"
2) "4"
3) "3"
4) "2"
5) "b"
6) "a"
7) "1"
127.0.0.1:6379> sdiff setr01 set02
(empty list or set)
127.0.0.1:6379> sdiff set01 set02 # 在set01中存在,在set02中不存在
1) "4"
2) "5"
127.0.0.1:6379> sdiff set02 set01 # 在set02中存在,在set01中不存在
1) "b"
2) "a"
3.1.4 哈希Hash
类似java里面的Map<String,Object>
KV模式不变,但V是一个键值对
hset/hget/hmset/hmget/hgetall/hdel:添加/得到/多添加/多得到/得到全部/删除属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25127.0.0.1:6379> hset user id 1001 # 添加user,值为id=1001
(integer) 1
127.0.0.1:6379> hget user
(error) ERR wrong number of arguments for 'hget' command
127.0.0.1:6379> hget user id # 查询user,必须指明具体的字段 "1001"
127.0.0.1:6379> hmset student id 101 name tom age 22 # 添加学生student,属性一堆
OK127.0.0.1:6379> hget student name # 获取学生名字
"tom"
127.0.0.1:6379> hmget student name age # 获取学生年龄
1) "tom"
2) "22"
127.0.0.1:6379> hgetall student # 获取学生全部信息
1) "id"
2) "101"
3) "name"
4) "tom"
5) "age"
6) "22"
127.0.0.1:6379> hdel student age # 删除学生年龄属性
(integer) 1 # 删除成功
127.0.0.1:6379> hgetall student
1) "id"
2) "101"
3) "name"
4) "tom"hlen:返回元素的属性个数
1
2
3
4
5
6
7127.0.0.1:6379> hgetall student
1) "id"
2) "101"
3) "name"
4) "tom"
127.0.0.1:6379> hlen student
(integer) 2 # student属性的数量,id和name,共两个属性hexists:判断元素是否存在某个属性
1
2
3
4127.0.0.1:6379> hexists student name # student中是否存在name属性
(integer) 1 # 存在
127.0.0.1:6379> hexists student age # student中是否存在age属性
(integer) 0 # 不存在hkeys/hvals:获得属性的所有key/获得属性的所有value
1
2
3
4
5
6127.0.0.1:6379> hkeys student # 获取student所有的属性名
1) "id"
2) "name"
127.0.0.1:6379> hvals student # 获取student所有属性的值(内容)
1) "101"
2) "tom"hincrby/hincrbyfloat:自增(整数)/自增(小数)
1
2
3
4
5
6
7
8
9
10
11
12127.0.0.1:6379> hmset student id 101 name tom age 22
OK
127.0.0.1:6379> hincrby student age 2 # 自增整数2
(integer) 24
127.0.0.1:6379> hget student age
"24"
127.0.0.1:6379> hmset user id 1001 money 1000
OK
127.0.0.1:6379> hincrbyfloat user money 5.5 # 自增小数5.5
"1005.5"
127.0.0.1:6379> hget user money
"1005.5"hsetnx:添加的时候,先判断是否存在
1
2
3
4
5
6
7
8
9
10
11
12
13hsetnx student age 18 # 添加时,判断age是否存在
(integer) 0 # 添加失败,因为age已存在
hsetnx student sex 男 # 添加时,判断sex是否存在
(integer) 1 # 添加成功,因为sex不存在
hgetall student
1) "id"
2) "101"
3) "name"
4) "tom"
5) "age"
6) "24"
7) "sex"
8) "\xe7\x94\xb7" # 可以添加中文,但是显示为乱码(后期解决)
3.1.5 有序集合Zset
真实需求:
充10元可享vip1;
充20元可享vip2;
充30元可享vip3;
以此类推…
zadd/zrange (withscores):添加/查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19zadd zset01 10 vip1 20 vip2 30 vip3 40 vip4 50 vip5
(integer) 5
zrange zset01 0 -1 # 查询数据
1) "vip1"
2) "vip2"
3) "vip3"
4) "vip4"
5) "vip5"
zrange zset01 0 -1 withscores # 带着分数查询数据
1) "vip1"
2) "10"
3) "vip2"
4) "20"
5) "vip3"
6) "30"
7) "vip4"
8) "40"
9) "vip5"
10) "50"zrangebyscore:模糊查询
- ( : 不包含
- limit:跳过几个截取几个
1
2
3
4
5
6
7
8
9
10
11
12
13
14127.0.0.1:6379> zrangebyscore zset01 20 40 # 20 <= score <= 40
1) "vip2"
2) "vip3"
3) "vip4"
127.0.0.1:6379> zrangebyscore zset01 20 (40 # 20 <= score < 40
1) "vip2"
2) "vip3"
127.0.0.1:6379> zrangebyscore zset01 (20 (40 # 20 < score < 40
1) "vip3"
127.0.0.1:6379> zrangebyscore zset01 10 40 limit 2 2 # 10 <= score <= 40,共返回四个,跳过前2个,取2个
1) "vip3"
2) "vip4"
127.0.0.1:6379> zrangebyscore zset01 10 40 limit 2 1 # 20 <= score <= 40,共返回四个,跳过前2个,取1个
1) "vip3"zrem:删除元素
1
2127.0.0.1:6379> zrem zset01 vip5 # 移除vip5
(integer) 1zcard/zcount/zrank/zscore:集合长度/范围内元素个数/得元素下标/通过值得分数
1
2
3
4
5
6
7
8127.0.0.1:6379> zcard zset01 # 集合中元素的个数
(integer) 4
127.0.0.1:6379> zcount zset01 20 30 # 分数在20~40之间,共有几个元素
(integer) 2
127.0.0.1:6379> zrank zset01 vip3 # vip3在集合中的下标(从上向下)
(integer) 2
127.0.0.1:6379> zscore zset01 vip2 # 通过元素获得对应的分数
"20"zrevrank:逆序找下标(从下向上)
1
2127.0.0.1:6379> zrevrank zset01 vip3
(integer) 1zrevrange:逆序查询
1
2
3
4
5
6
7
8
9
10127.0.0.1:6379> zrange zset01 0 -1 # 顺序查询
1) "vip1"
2) "vip2"
3) "vip3"
4) "vip4"
127.0.0.1:6379> zrevrange zset01 0 -1 # 逆序查询
1) "vip4"
2) "vip3"
3) "vip2"
4) "vip1"zrevrangebyscore:逆序范围查找
1
2
3
4127.0.0.1:6379> zrevrangebyscore zset01 30 20 # 逆序查询分数在30~20之间的 (注意,先写大值,再写小值)
1) "vip3"
2) "vip2"
127.0.0.1:6379> zrevrangebyscore zset01 20 30 # 如果小值在前,则结果为null (empty list or set)
3.3 持久化
3.3.1 RDB
Redis DataBase
- 在指定的时间间隔内,将内存中的数据集的快照写入磁盘;
- 默认保存在/usr/local/bin中,文件名dump.rdb;
3.3.1.1 自动备份
- redis是内存数据库,当我们每次用完redis,关闭linux时,按道理来说,内存释放,redis中的数据也会随之消失
- 为什么我们再次启动redis的时候,昨天的数据还在,并没有消失呢?
- 正是因为,每次关机时,redis会自动将数据备份到一个文件中 :/usr/local/bin/dump.rdb
- 接下来我们就来全方位的认识 自动备份机制
默认的自动备份策略不利于我们测试,所以修改redis.conf文件中的自动备份策略
1
2
3
4
5
6vim redis.conf
/SNAP
save 900 1
save 120 10
save 60 10000当然如果你只是用Redis的缓存功能,不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。可以直接一个空字符串来实现停用:save “”
使用shutdown模拟关机 ,关机之前和关机之后,对比dump.rdb文件的更新时间。注意:当我们使用shutdown命令,redis会自动将数据库备份,所以,dump.rdb文件创建时间更新了
开机启动redis,我们要在120秒内保存10条数据,再查看dump.rdb文件的更新时间(开两个终端窗口,方便查看)
120秒内保存10条数据这一动作触发了备份指令,目前,dump.rdb文件中保存了10条数据,将dump.rdb拷贝一份dump10.rdb,此时两个文件中都保存10条数据
既然有数据已经备份了,那我们就肆无忌惮的将数据全部删除flushall,再次shutdown关机
再次启动redis,发现数据真的消失了,并没有按照我们所想的 将dump.rdb文件中的内容恢复到redis中。为什么?
因为,当我们保存10条以上的数据时,数据备份起来了;
然后删除数据库,备份文件中的数据,也没问题;
但是,问题出在shutdown上,这个命令一旦执行,就会立刻备份,将删除之后的空数据库生成备份文件,将之前装10条数据的备份文件覆盖掉了。所以,就出现了上图的结果。自动恢复失败。
怎么解决这个问题呢?要将备份文件再备份
将dump.rdb文件删除,将dump10.rdb重命名为dump.rdb
启动redis服务,登录redis,数据10条,全部恢复!
3.3.1.2 手动备份
- 之前自动备份,必须更改好多数据,例如上边,我们改变了十多条数据,才会自动备份;
- 现在,我只保存一条数据,就想立刻备份,应该怎么做?
- 每次操作完成,执行命令 save 就会立刻备份
3.3.1.3 与RDB相关的配置
- stop-writes-on-bgsave-error:进水口和出水口,出水口发生故障与否
- yes:当后台备份时候反生错误,前台停止写入
- no:不管死活,就是往里怼
- rdbcompression:对于存储到磁盘中的快照,是否启动LZF压缩算法,一般都会启动,因为这点性能,多买一台电脑,完全搞定N个来回了。
- yes:启动
- no:不启动(不想消耗CPU资源,可关闭)
- dbfilename:快照备份文件名字
- dir:快照备份文件保存的目录,默认为当前目录
优势and劣势
- 优:适合大规模数据恢复,对数据完整性和一致行要求不高;
- 劣:一定间隔备份一次,意外down掉,就失去最后一次快照的所有修改
3.3.2 AOF
Append Only File
- 以日志的形式记录每个写操作;
- 将redis执行过的写指令全部记录下来(读操作不记录);
- 只许追加文件,不可以改写文件;
- redis在启动之初会读取该文件从头到尾执行一遍,这样来重新构建数据;
3.3.2.1 开启AOF
为了避免失误,最好将redis.conf总配置文件备份一下,然后再修改内容如下:
1
2appendonly yes
appendfilename appendonly.aof重新启动redis,以新配置文件启动
1
redis-server /usr/local/redis5.0.4/redis.conf
连接redis,加数据,删库,退出
查看当前文件夹多一个aof文件,看看文件中的内容,保存的都是 写 操作
- 文件中最后一句要删除,否则数据恢复不了
- 编辑这个文件,最后要 :wq**!** 强制执行
只需要重新连接,数据恢复成功
3.3.2.2 共存?谁优先?
我们查看redis.conf文件,AOF和RDB两种备份策略可以同时开启,那系统会怎样选择?
动手试试,编辑appendonly.aof,胡搞乱码,保存退出
启动redis 失败,所以是AOF优先载入来恢复原始数据!因为AOF比RDB数据保存的完整性更高!
修复AOF文件,杀光不符合redis语法规范的代码
1
reids-check-aof --fix appendonly.aof
3.3.2.3 与AOF相关的配置
- appendonly:开启aof模式
- appendfilename:aof的文件名字,最好别改!
- appendfsync:追写策略
- always:每次数据变更,就会立即记录到磁盘,性能较差,但数据完整性好
- everysec:默认设置,异步操作,每秒记录,如果一秒内宕机,会有数据丢失
- no:不追写
- no-appendfsync-on-rewrite:重写时是否运用Appendfsync追写策略;用默认no即可,保证数据安全性。
- AOF采用文件追加的方式,文件会越来越大,为了解决这个问题,增加了重写机制,redis会自动记录上一次AOF文件的大小,当AOF文件大小达到预先设定的大小时,redis就会启动AOF文件进行内容压缩,只保留可以恢复数据的最小指令集合
- auto-aof-rewrite-percentage:如果AOF文件大小已经超过原来的100%,也就是一倍,才重写压缩
- auto-aof-rewrite-min-size:如果AOF文件已经超过了64mb,才重写压缩
3.3.3 总结(如何选择?)
- RDB:只用作后备用途,建议15分钟备份一次就好
- AOF:
- 在最恶劣的情况下,也只丢失不超过2秒的数据,数据完整性比较高,但代价太大,会带来持续的IO
- 对硬盘的大小要求也高,默认64mb太小了,企业级最少都是5G以上;
- 后面要学习的master/slave才是新浪微博的选择!!
3.4 事务
- 可以一次执行多个命令,是一个命令组,一个事务中,所有命令都会序列化(排队),不会被插队;
- 一个队列中,一次性,顺序性,排他性的执行一系列命令
- 三特性
- 隔离性:所有命令都会按照顺序执行,事务在执行的过程中,不会被其他客户端送来的命令打断
- 没有隔离级别:队列中的命令没有提交之前都不会被实际的执行,不存在“事务中查询要看到事务里的更新,事务外查询不能看到”这个头疼的问题
- 不保证原子性:冤有头债有主,如果一个命令失败,但是别的命令可能会执行成功,没有回滚
- 三步走
- 开启multi
- 入队queued
- 执行exec
- 与关系型数据库事务相比,
- multi:可以理解成关系型事务中的 begin
- exec :可以理解成关系型事务中的 commit
- discard :可以理解成关系型事务中的 rollback
3.4.1 一起生
开启事务,加入队列,一起执行,并成功
1 | 127.0.0.1:6379> multi # 开启事务 |
3.4.2 一起死
放弃之前的操作,恢复到原来的值
1 | 127.0.0.1:6379> multi # 开启事务 |
3.4.3 一粒老鼠屎坏一锅汤
一句报错,全部取消,恢复到原来的值
1 | 127.0.0.1:6379> multi |
3.4.4 冤有头债有主
追究责任,谁的错,找谁去
1 | 127.0.0.1:6379> multi |
3.4.5 watch监控
测试:模拟收入与支出
正常情况下:
1
2
3
4
5
6
7
8
9
10
11
12
13127.0.0.1:6379> set in 100 # 收入100元
OK
127.0.0.1:6379> set out 0 # 支出0元
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby in 20 # 收入-20
QUEUED
127.0.0.1:6379> incrby out 20 # 支出+20
QUEUED
127.0.0.1:6379> exec
1) (integer) 80
2) (integer) 20 # 结果,没问题!特殊情况下:
1
2
3
4
5
6
7
8
9
10127.0.0.1:6379> watch in # 监控收入in
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby in 20
QUEUED
127.0.0.1:6379> incrby out 20
QUEUED
127.0.0.1:6379> exec
(nil) # 在exec之前,我开启了另一个窗口(线程),对监控的in做了修改,所以本次的事务将 被打断(失效),类似于“乐观锁”unwatch:取消watch命令对所有key的操作
- 一旦执行了exec命令,那么之前加的所有监控自动失效!
3.5 Redis的发布订阅
进程间的一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。例如:微信订阅号
订阅一个或多个频道
1
2
3
4
5
6
7
8
9
10
11
12
13
14127.0.0.1:6379> subscribe cctv1 cctv5 cctv6 # 1.订阅三个频道
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "cctv1"
3) (integer) 1
1) "subscribe"
2) "cctv5"
3) (integer) 2
1) "subscribe"
2) "cctv6"
3) (integer) 3
1) "message" # 3.cctv5接收到推送过来的信息
2) "cctv5"
3) "NBA"发送消息
1
2127.0.0.1:6379> publish cctv5 NBA # 2.发送消息给cctv5
(integer) 1
3.5 主从复制
- 就是 redis集群的策略
- 配从(库)不配主(库):小弟可以选择谁是大哥,但大哥没有权利去选择小弟
- 读写分离:主机写,从机读
3.5.1 一主二仆
准备三台服务器,并修改redis.conf
1
bind 0.0.0.0
启动三台redis,并查看每台机器的角色,都是master
1
info replication
测试开始
首先,将三个机器全都清空,第一台添加值
1
mset k1 v1 k2 v2
其余两台机器,复制(找大哥)
1
slaveof 192.168.204.141 6379
第一台再添加值
1
set k3 v3
- **思考1:**slave之前的k1和k2是否能拿到?
- **思考2:**slave之后的k3是否能拿到?
- **思考3:**同时添加k4,结果如何?
- **思考4:**主机shutdown,从机如何?
- **思考5:**主机重启,从机又如何?
- **思考6:**从机死了,主机如何?从机归来身份是否变化?
3.5.2 血脉相传
一个主机理论上可以多个从机,但是这样的话,这个主机会很累
我们可以使用java面向对象继承中的传递性来解决这个问题,减轻主机的负担
形成祖孙三代:
1
2
3
4127.0.0.1:6379> slaveof 192.168.204.141 6379 # 142跟随141
OK
127.0.0.1:6379> slaveof 192.168.204.142 6379 # 143跟随142 '
OK
3.5.3 谋权篡位
1个主机,2个从机,当1个主机挂掉了,只能从2个从机中再次选1个主机
国不可一日无君,军不可一日无帅
手动选老大
模拟测试:1为master,2和3为slave,当1挂掉后,2篡权为master,3跟2
1
slaveof no one # 2上执行,没有人能让我臣服,那我就是老大
1
slaveof 192.168.204.142 6379 # 3跟随2号
**思考:**当1再次回归,会怎样?
- 2和3已经形成新的集群,和1没有任何的关系了。所以1成为了光杆司令
3.5.4 复制原理

完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求
- 全量复制:Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份slave接收到数据文件后,存盘,并加载到内存中;(步骤1234)
- 增量复制:Slave初始化后,开始正常工作时主服务器发生的写操作同步到从服务器的过程;(步骤56)但,只要是重新连接master,一次性(全量复制)同步将自动执行;
- Redis主从同步策略:主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。
- 当然,如果有需要,slave 在任何时候都可以发起全量同步。
- redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
3.5.5 哨兵模式
自动版的谋权篡位!
有个哨兵一直在巡逻,突然发现!!!!!老大挂了,小弟们会自动投票,从众小弟中选出新的老大
Sentinel是Redis的高可用性解决方案:
- 由一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器,以及所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求
模拟测试
1主,2和3从
每一台服务器中创建一个配置文件sentinel.conf,名字绝不能错,并编辑sentinel.conf
1
2# sentinel monitor 被监控主机名(自定义) ip port 票数
sentinel monitor redis141 192.168.204.141 6379 1启动服务的顺序:主Redis –> 从Redis –> Sentinel1/2/3
1
redis-sentinel sentinel.conf
将1号老大挂掉,后台自动发起激烈的投票,选出新的老大
1
2127.0.0.1:6379> shutdown
not connected> exit查看最后权利的分配
- 3成为了新的老大,2还是小弟
如果之前的老大再次归来呢?
- 1号再次归来,自己成为了master,和3平起平坐
- 过了几秒之后,被哨兵检测到了1号机的归来,1号你别自己玩了,进入集体吧,但是新的老大已经产生了,你只能作为小弟再次进入集体!
3.5.6 缺点
- 由于所有的写操作都是在master上完成的;
- 然后再同步到slave上,所以两台机器之间通信会有延迟;
- 当系统很繁忙的时候,延迟问题会加重;
- slave机器数量增加,问题也会加重
3.6 总配置redis.conf 详解
1 | Redis 配置文件示例 |
- 通常情况下,默认的配置足够你解决问题!
- 没有极特殊的要求,不要乱改配置!
3.7 Jedis
java和redis打交道的API客户端
1 | <dependency> |
3.7.1 连接redis
1 | public static void main(String[] args) { |
3.7.2 常用API
1 | private void testString(){ |
3.7.3 事务
- 初始化余额和支出
1 | set yue 100 |
1 | public static void main(String[] args) throws Exception{ |
- 模拟网络延迟:,10秒内,进入linux修改余额为5,这样,余额<支出,就会进入if
3.7.4 JedisPool
- redis的连接池技术
- 详情:https://help.aliyun.com/document_detail/98726.html
1 | <dependency> |
- 使用单例模式进行优化
1 | import jdk.nashorn.internal.scripts.JD; |
- 测试类
1 | /** |
3.8 高并发下的分布式锁
- 经典案例:秒杀,抢购优惠券等
3.8.1 搭建工程并测试单线程
1 | <packaging>war</packaging> |
1 |
|
1 |
|
1 | package controller; |
3.8.2 高并发测试
- 启动两次工程,端口号分别8001和8002
- 使用nginx做负载均衡
1 | upstream sga{ |
1 | /usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf |
- 使用 JMeter 模拟1秒内发出100个http请求,会发现同一个商品会被两台服务器同时抢购!
3.8.3 实现分布式锁的思路
因为redis****是单线程的,所以命令也就具备原子性,使用setnx命令实现锁,保存k-v
- 如果k不存在,保存(当前线程加锁),执行完成后,删除k表示释放锁
- 如果k已存在,阻塞线程执行,表示有锁
如果加锁成功,在执行业务代码的过程中出现异常,导致没有删除k(释放锁失败),那么就会造成死锁(后面的所有线程都无法执行)
- 设置过期时间,例如10秒后,redis自动删除
高并发下,由于时间段等因素导致服务器压力过大或过小,每个线程执行的时间不同
- 第一个线程,执行需要13秒,执行到第10秒时,redis自动过期了k(释放锁)
- 第二个线程,执行需要7秒,加锁,执行第3秒(锁 被释放了,为什么,是被第一个线程的finally主动deleteKey释放掉了)
- 。。。连锁反应,当前线程刚加的锁,就被其他线程释放掉了,周而复始,导致锁会永久失效
给每个线程加上唯一的标识UUID随机生成,释放的时候判断是否是当前的标识即可
问题又来了,过期时间如果设定?
- 如果10秒太短不够用怎么办?
- 设置60秒,太长又浪费时间
- 可以开启一个定时器线程,当过期时间小于总过期时间的1/3时,增长总过期时间(吃仙丹续命!)
自己实现分布式锁,太难了!
3.8.4 Redisson
- Redis 是最流行的 NoSQL 数据库解决方案之一,而 Java 是世界上最流行(注意,我没有说“最 好”)的编程语言之一。
- 虽然两者看起来很自然地在一起“工作”,但是要知道,Redis 其实并没有对 Java 提供原生支持
- 相反,作为 Java 开发人员,我们若想在程序中集成 Redis,必须使用 Redis 的第三方库。
- 而 Redisson 就是用于在 Java 程序中操作 Redis 的库,它使得我们可以在程序中轻松地使用Redis。
- Redisson 在 java.util 中常用接口的基础上,为我们提供了一系列具有分布式特性的工具类。
1 | package controller; |
- 实现分布式锁的方案其实有很多,我们之前用过的zookeeper的特点就是高可靠性,现在我们用的redis特点就是高性能。
- 目前分布式锁,应用最多的仍然是“Redis”